
When you hear about amazing AI tools like ChatGPT, Grok, Gemini, or GitHub Copilot, it’s easy to wonder: “What’s their secret? Are they powered by super-secret, complex math equations?” The truth is, it’s “kind of.”
At their heart, these AIs do use some fundamental math. Think of these as the basic “building blocks” of AI:

These equations are important, but here’s the kicker: they’re not secret! You can actually write these equations in a few lines of code.
Because Equations Alone Aren’t Enough
The equations aren’t secret. ⬛× The data is. ⬛
You can implement every one of those equations in a few lines of Python or even in Excel. But without the massive datasets — cleaned, labeled, aligned, structured — these equations are just dead machinery. What makes OpenAI, Google, or Anthropic, successful isn’t just their models.
It’s the mountains of data they feed into them.
Let’s say you type into Grok:
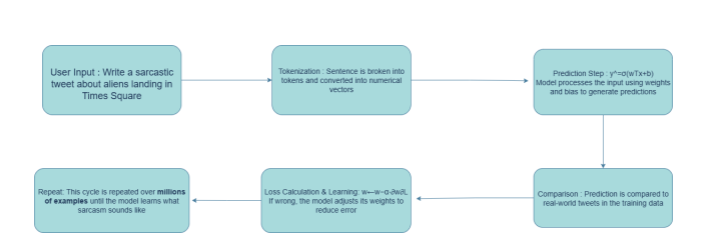
AI = Equations + Data + Compute
What is “Data” in the World of AI?
In our AI construction project, “data” isn’t just a pile of neatly organized blueprints. It’s every piece of information we gather about houses:
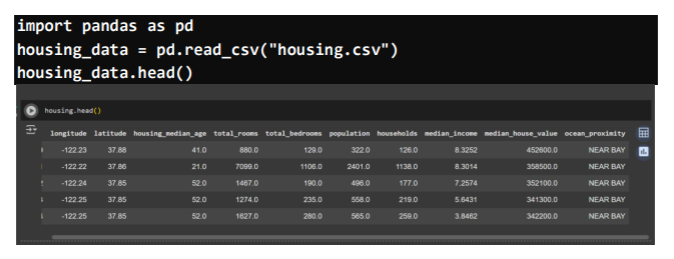
- Structured Data: Think of it as organized lists – tables, spreadsheets, databases. For our predictor, this might be the number of bedrooms, square footage, or the year a house was built, neatly laid out in a CSV file.
- Unstructured Data: This is the messy stuff – text descriptions of neighborhoods, photos of interiors, or audio recordings of market trends. These are like quick sketches on napkins or whispered conversations – valuable, but not easily digestible by our AI tools without extra work.
Phase 1: Getting Our Materials In Order (and Cleaning Up the Mess)

Before we can even think about building, we need to gather our raw materials – our housing.csv file. But sometimes, even this first step can hit unexpected snags, like hitting a hidden rock instead of digging the foundation smoothly.
You might encounter errors that feel like frustrating roadblocks:
- UnicodeDecodeError: “Wait, this blueprint is in a foreign language I don’t understand!” (Often means the file encoding is wrong).
- File not found: “Where did I put that crucial blueprint?!” (The file path is incorrect).
- NaNs (missing values): “Uh oh, this section of the blueprint is completely blank!” (Crucial information is absent).
We need a resilient way to bring our data in, like having a backup plan for our tools:

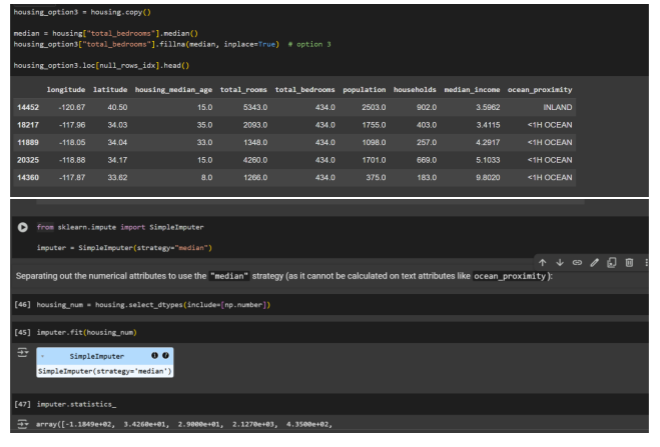
Always, always examine your data! Just like a skilled architect reviews every blueprint and material before construction begins, we must deeply understand the structure and quality of our data before modeling.
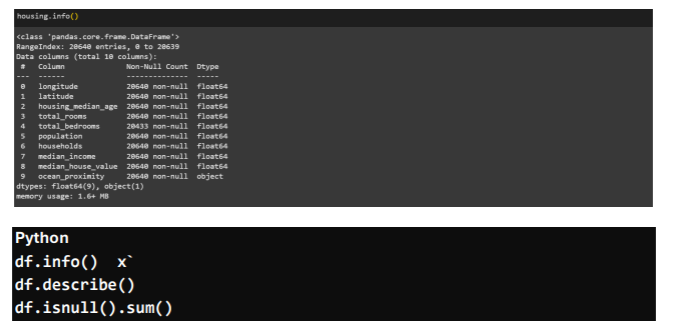
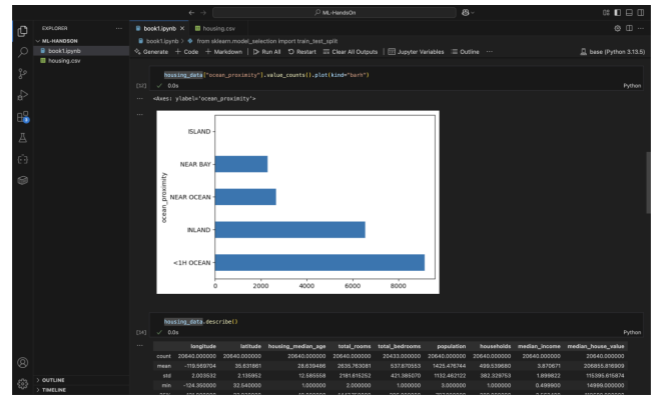
Phase 2: Fixing the “Missing Pieces” s “Translating Languages”
Missing values in data are like holes in a wall — they weaken your model. To fix them, you can either drop rows, drop columns, or fill the missing values (called imputation). Filling with the median is a safe choice, especially when your data has outliers.
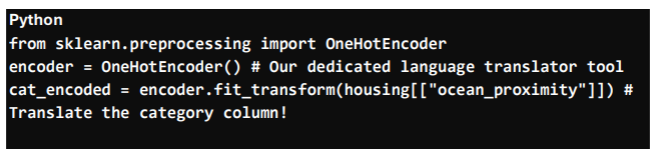
Text columns like “Near Ocean” or “Inland” also need fixing — models only understand numbers. The best way is to use One-Hot Encoding, which turns each category into its own column with 0s and 1s, so there’s no confusion or fake ranking.
Encoding Categorical Variables: Making Everyone Speak “Numbers”
- Label Encoding (use with caution): Simply assigning 0, 1, 2, 3 to categories. The problem? Our AI might mistakenly interpret “2” as somehow “better” or “larger” than “1,” creating a fake order that doesn’t exist in reality. This would be like telling your builder that a “brick” is inherently superior to a “stone” just because it’s assigned a higher number – it introduces unintended bias.
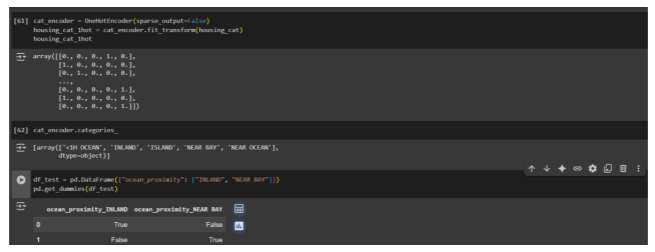
- One-Hot Encoding (our preferred method): This is like creating a separate “yes/no” question (a binary flag) for each category. For “Near Ocean,” we create a new column: Is_Near_Ocean (1 if the house is near the ocean, 0 if not). This avoids creating fake hierarchies and is generally safer for nominal (unordered) categories.
The result looks like a series of yes/no flags (1s and 0s), where each row’s ‘1’ indicates its specific category:
Phase 3: Balancing the Scales (Making Sure All Measurements Matter Equally)
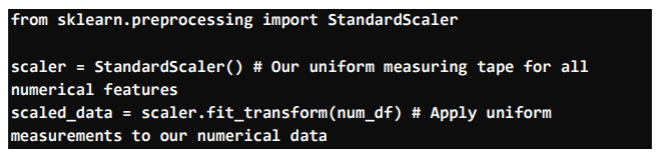
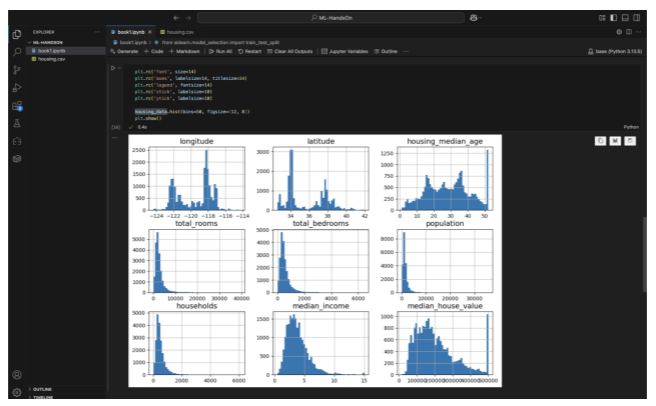
By doing this, every feature contributes proportionally to the model’s learning, preventing features with large magnitudes from unfairly dominating the process.
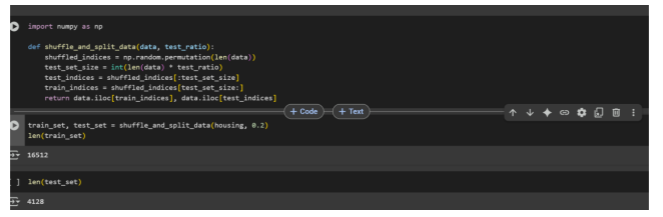
Phase 4: The Practice Run vs. The Final Exam (Splitting Our Data)
You wouldn’t let an architect build your dream home without first seeing examples of their previous work, would you? And you certainly wouldn’t give them all the blueprints, then judge their skill based only on those exact blueprints.
- Training Set = Practice Problems: This is the bulk of our data, used to train our AI model. It’s like giving our architect a detailed set of practice designs and problems to learn from and hone their skills.
- Test Set = Final Exam: This is a completely separate portion of the data, kept secret from the AI during its training phase. It’s used to evaluate how well our model performs on unseen data – data it has never encountered before. It’s the ultimate test of whether our architect truly learned to design or just memorized the practice problems.
Why is this separation crucial? If our AI performs brilliantly on the training data but miserably on the test data, it’s a phenomenon called overfitting. This means it memorized the practice problems instead of truly understanding the underlying principles and patterns of house pricing. It’s like an architect who can only build that exact house they practiced, but can’t design a new one from scratch.
What if our data has class imbalance (e.g., very few luxury homes or island properties)? If a simple random split puts all “Island” homes into the training set and none into the test set, your AI will have no idea how to predict prices for islands when it encounters them in the real world!
- Stratified Sampling: This is like making sure your practice problems and your final exam have a similar, proportional mix of different house types (e.g., a balanced representation of “Near Ocean,” “Inland,” “Island” homes, or different income categories).
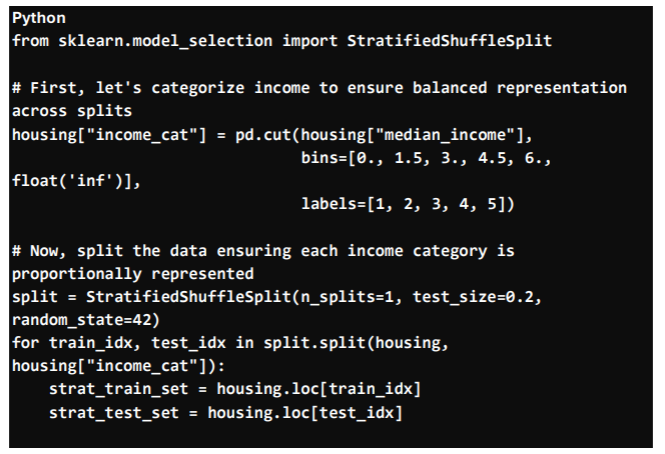
This method is vital for building robust models that perform well across all segments of your data.
Phase 5: Building the Assembly Line (Pipelines)
Imagine manually carrying each brick, mixing cement by hand, and placing every tile individually for every single house. Inefficient, error-prone, and exhausting, right?
Manual data preprocessing, especially when you have many steps, can get incredibly messy and error-prone. Scikit-Learn’s Pipelines are like setting up an automated, streamlined assembly line for your data. You define the sequence of cleaning, transforming, and scaling steps once, and then apply it consistently to all your data – both training and new, incoming data.
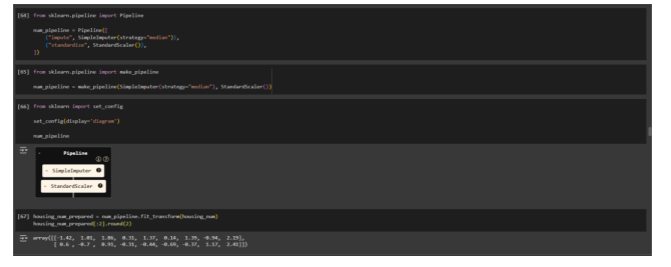
This ensures that every piece of data goes through the exact same rigorous cleaning and preparation process, making your AI construction project robust, repeatable, and ready for deployment.
Conclusion: The Foundation of AI Excellence
Data preprocessing, often overlooked in the dazzling spotlight of AI algorithms, is truly the unsung hero. It’s the meticulous work of preparing your raw materials, fixing imperfections, and translating complexities into a language your AI can understand.
Without this critical phase, even the most advanced machine learning models would be like magnificent buildings erected on shaky foundations – impressive to look at, but ultimately destined to crumble.
By mastering data preprocessing, you don’t just become a data scientist; you become a true architect of AI, ensuring that every intelligent system you build is not only powerful but also reliable, fair, and ready for the real world.



