Discover how Transformer architecture revolutionized AI, enabling ChatGPT, BERT, and modern language models to understand context like never before.
Introduction: The AI Revolution You’re Already Using
Think about the last time you used ChatGPT, asked Siri a question, or let Google Translate help you understand a foreign language. Behind these everyday interactions lies a technological breakthrough that fundamentally changed how machines understand human language: the Transformer architecture.
Transformers are not just another AI model; they are a core architecture that changes how machines process language, images, and other sequential data. In fact, most modern Large Language Models (LLMs) are built using the Transformer architecture.
This comprehensive guide delves into the fundamentals of Transformers. Whether you’re a developer looking to understand the technology behind LLMs, a business leader evaluating AI solutions, or simply curious about how modern AI actually works, you’ll find clear explanations in a simple and beginner-friendly way.
What Is a Transformer in AI?
A Transformer is a type of neural network architecture designed to process sequential data, such as sentences, audio signals, or image patches.
Unlike older models that read data step by step, Transformers can examine all parts of the input simultaneously, understanding how each element relates to every other element.
Simple Example
Sentence:
“I went to the bank to deposit money.”
A transformer understands that
- “Bank” refers to a financial institution, not a riverbank. This approach considers all words together.
This ability to understand context is what makes Transformers powerful.
Transformer architecture
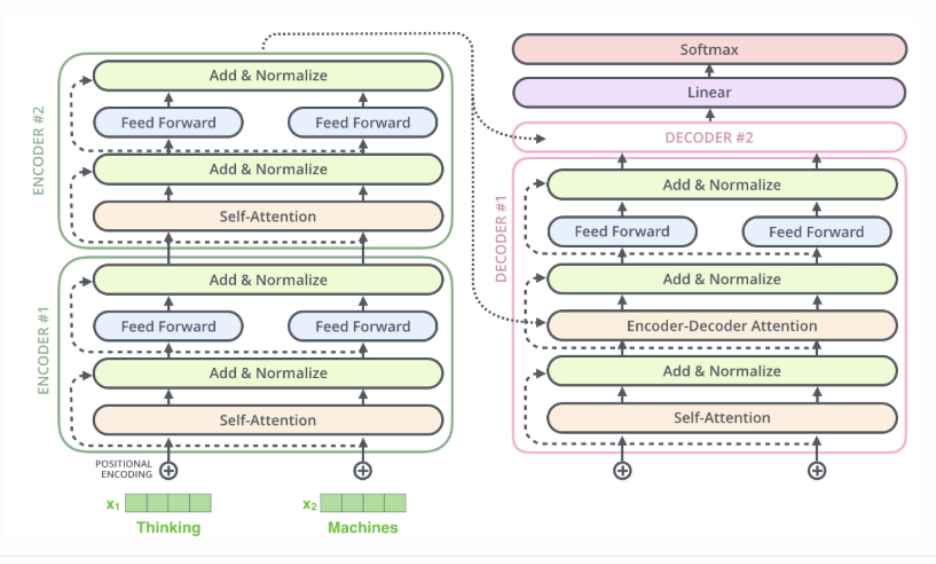
1. Input Embeddings
- The input text is first split into tokens (words or sub-words).
- Each token is converted into a vector of numbers called an embedding.
- These vectors capture the meanings and relationships among words, enabling the model to process language mathematically.
2. Positional Encoding
- Transformers do not naturally understand word order.
- Positional encoding adds position information to each token embedding.
- This helps the model know which word comes first, next, and last in a sentence.
3. Transformer Block
A transformer model contains multiple stacked transformer blocks. Each block has two main parts:
a) Self-Attention
- Allows the model to focus on important words in the sentence.
- Helps understand context (e.g., the word “lies” means different things depending on nearby words).
Technical note: Self-attention computes three vectors for each token (Query, Key, Value) and then uses dot-product attention to determine how much focus each token should give to every other token.
b) Feed-Forward Neural Network
- Processes the attention output to learn deeper patterns.
- Includes:
- Residual connections for better information flow
- Layer normalization for stable training
- Linear layers to adjust values for the task
4. Linear Layer
- Converts the internal representation into scores for each possible output token.
- These scores are called logits.
5. Softmax Layer
- Converts logits into probabilities.
- The token with the highest probability is chosen as the final output.
Why Are Transformers Important?
Transformers became a breakthrough in Artificial Intelligence because they solved many limitations of older models, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks.
1. Better Understanding of Context
Traditional models read text word by word, which makes it challenging to understand long sentences. Transformers, on the other hand, analyze all words at the same time using self-attention.
This function allows them to:
- Understand long and complex sentences
- Capture relationships between words even if they are far apart.
Example:
“The movie that we watched last night was incredible.”
A Transformer correctly understands that “was incredible” refers to “the movie,” even though many words come in between.
2. Faster Training and Processing
Because Transformers work in parallel:
- They process entire sentences at once.
- Training time is much faster compared to older models.
This efficiency makes Transformers ideal for training on massive datasets, which is essential for modern AI systems.
3. Ability to Handle Long-Range Dependencies
One of the most significant failures of pre-Transformer models was their inability to maintain context over long sequences.
Transformers maintain context across:
- Thousands of tokens
- Multiple documents
- Complex narratives
This is why they perform so well in tasks like summarization and question answering.
4. Scalability for Large Models
Transformers scale extremely well when:
- More data is added.
- Model size is increased.
This scalability has enabled the creation of Large Language Models (LLMs) such as the following:
- GPT (Generative Pre-trained Transformer)
- BERT
- T5
- Claude
Types of Transformer Models: Encoder, Decoder, and Hybrid
Not all Transformers are created equally. Depending on the task, different architectural variants excel:
1. Encoder-Only Transformers
- Focus on understanding the input text.
- Commonly used for classification and search tasks
Example models:
- BERT
- RoBERTa
Use cases:
- Sentiment analysis •Text classification •Information retrieval
2. Decoder-Only Transformers
- Focus on generating text.
- Predict the next word based on previous words.
Example models: GPT series
Use cases:
- Chatbots •Story generation •Code generation
3. Encoder–Decoder Transformers
- Combine understanding and generation
- One part reads input; the other produces output.
Example models:
- T5 (Text-to-Text Transfer Transformer)
- BART
Use cases:
- Machine translation •Text summarization •Question answering
Applications of Transformers in Artificial Intelligence
Transformers are used across many AI domains today.
1. Natural Language Processing (NLP)
NLP remains the primary application area for Transformers, powering:
- Chatbots (ChatGPT, virtual assistants)
- Language translation (Google Translate)
- Text summarization
- Question-answering systems
2. Computer Vision
The success of Transformers in NLP inspired researchers to adapt them for images, leading to Vision Transformers (ViTs).
Vision Transformers (ViTs) are used for:
- Image classification
- Object detection
- Medical Imaging
3. Speech and Audio Processing
Audio presents unique challenges due to its temporal and spectral complexity. Transformers have revolutionized this domain:
- Speech-to-text systems
- Voice assistants
- Audio classification
4. Recommendation Systems and Time-Series Data
Transformers excel at understanding patterns in sequential data, making them valuable for:
- Product recommendations
- Financial forecasting
- Anomaly detection
Limitations of Transformers
Despite their revolutionary impact, Transformers aren’t perfect. Understanding their limitations is crucial for realistic expectations and effective deployment.
1. High Computational Cost
- Require powerful GPUs or TPUs
- Training large models is expensive.
2. Large Data Requirements
- Perform best when trained on massive datasets.
- May struggle with limited data
3. Memory Usage
- Self-attention becomes costly for very long sequences.
The Road Ahead: Future Directions for Transformers
Transformer research continues to evolve rapidly. Here are the key areas that are pushing the boundaries:
- Multimodal unification: Models that natively understand text, images, audio, and video in a single architecture (GPT-4V, Gemini, others)
- Efficiency improvements: Making Transformers faster, smaller, and more accessible without sacrificing capability.
- Extended context: Pushing context windows to millions of tokens for whole-book understanding.
- Reasoning capabilities: Improving chain-of-thought, mathematical reasoning, and logical deduction
- Factual grounding: Reducing hallucinations through retrieval-augmented generation and fact-checking mechanisms
- Personalization: Models that adapt to individual users while preserving privacy
The Transformer architecture itself may continue evolving, potentially giving way to even more efficient attention mechanisms or entirely new paradigms.
Conclusion
Transformers have fundamentally reshaped artificial intelligence, moving it from narrow, task-specific tools to flexible, general-purpose systems that can understand and generate human-like text, analyze images, process speech, and more.
As research continues, newer variants aim to make Transformers faster, cheaper, and more efficient, ensuring they remain at the heart of AI innovation for years to come.
—
—
Keywords: Transformers in AI, Transformer architecture, self-attention mechanism, large language models, GPT, BERT, natural language processing, encoder-decoder models, Vision Transformers, machine learning, deep learning, neural networks, attention mechanism, LLMs, ChatGPT, Claude AI, artificial intelligence explained