Introduction: The Hidden Cost Crisis in AI Applications
Large Language Models (LLMs) are transforming enterprise software from chatbots and document processing systems to architecture analysis tools and pricing assistants. But as organizations scale AI-powered applications, they quickly face an uncomfortable truth:
LLM inference costs can become the single largest operational expense in your architecture.
On AWS, services like Amazon Bedrock, AWS Lambda, Amazon API Gateway, Amazon S3, Amazon DynamoDB, and Amazon ElastiCache make it easy to build production-grade AI systems.
But without cost-aware design:
- Every user request triggers a fresh LLM invocation
- Per-request costs escalate rapidly
- Latency increases
- Redundant processing multiplies
- Infrastructure load grows unnecessarily
This is where caching becomes critical, not as an optimization, but as a foundational architectural pillar.
In this guide, you’ll learn how to strategically reduce LLM costs using AWS caching, including multi-layer caching strategies, real-world use cases, TTL models, and best practices that deliver immediate ROI.
The Cost Problem: Why LLM Economics Needs Fixing
LLM operations are expensive due to:
- Compute-Intensive Inference – Each query requires significant GPU/CPU resources.
- Token-Based Pricing—Charges scale with both input and output tokens.
- Redundant Processing—Identical queries processed repeatedly.
- Retry Overhead—Failed requests and regenerations multiply costs.
- High-Traffic Workflows—Chat and automation generate enormous query volumes.
- Latency Costs—Slow responses impact user experience and business metrics.
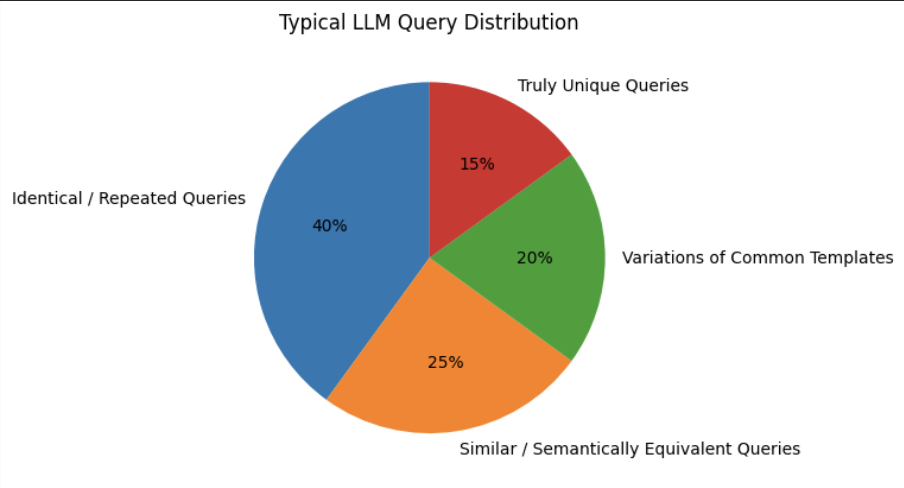
The Hidden Reality: Most Queries Are Redundant
Here’s the key insight: 60-80% of LLM queries in typical enterprise applications are repetitive or highly similar.
Multiple users ask the same questions; AI generates identical outputs, yet systems invoke the LLM every single time. This redundancy is your greatest cost-saving opportunity, and caching solves exactly this problem.
The Caching Solution
What Does “Caching” Mean in LLM Systems? In traditional systems, caching stores:
- API responses
- Database query results
- Web pages
In LLM-based systems, caching stores:
- Prompt → Response pairs
- Extracted structured data
- AI-generated documents
High-Level AWS Architecture for LLM Caching
Below is the AWS AI architecture with caching:
[Frontend / Client]
|
v
[API Gateway]
|
v
[AWS Lambda]
|
|--> Cache Check (Redis / DynamoDB)
| |
| └── Cache Hit → Return Response
|
└── Cache Miss
|
v
[Amazon Bedrock (LLM)]
|
v
[Store Response in Cache + DB]
|
v
[Return Response] This architecture ensures that the LLM is invoked only when necessary, providing fast responses for repeated queries and predictable costs at scale.
Types of Caching in LLM-Based AWS Systems
There is no one-size-fits-all cache. Mature systems use multiple caching layers.
1️⃣ In-Memory Cache (Redis / ElastiCache)
Best For: Real-time chatbots, architecture tools, pricing assistants
Key Benefits:
- Sub-10ms latency
- Ideal for high-frequency queries
- Horizontally scalable
- 40–50% cache hit rate
When to Use: Choose Redis when latency is critical, and query patterns favor short-lived, high-frequency cache entries.
2️⃣ DynamoDB-Based Persistent Cache
Best For: Compliance-heavy systems, audit trails, durable cache requirements
Key Benefits:
• Fully serverless scaling • Built-in TTL support
• Strong consistency • Survives infrastructure changes
Schema Design
Partition Key: Prompt Hash
Attributes:
• AI Response • Model Version • Created Timestamp
• Token Count • TTL
3️⃣ S3-Based Output Caching
Best For: Large AI-generated documents, PDFs, reports, and architecture diagrams
Key Benefits:
• Extremely cost-effective • Lifecycle policies
• CloudFront integration • Versioning support
Pro Tip: Use S3 Intelligent-Tiering for automatic cost optimization.
Multi-Layer Caching Strategy (Three-Tier Approach)
The most cost-efficient systems use layered caching:
User Request
↓[Tier 1: Redis Cache] - 40–50% hit rate
↓ (miss)[Tier 2: DynamoDB Cache] - 15–25% additional hits
↓ (miss)[Tier 3: S3 Cached Output] - 5–10% additional hits
↓ (miss)[Amazon Bedrock] - Generate fresh responseResult: 70–85% of requests are resolved without touching the LLM. P95 latency stays under 100ms.
The Three-Tier AWS Caching Strategy (Detailed Breakdown)
Tier 1: Exact Match Cache (Fastest)
Service: Amazon ElastiCache (Redis)
- Stores exact prompt–response pairs
- Handles repeated identical queries
- 40–50% hit rate
- Sub-millisecond latency
Expected Savings: 40–50% reduction in LLM calls
Tier 2: Semantic Cache
Services: Amazon OpenSearch + Bedrock (Titan Embeddings)
- Handles paraphrased queries
- It uses vector similarity instead of text matching.
- 15–25% additional hit rate
Key Configuration Parameters
- Similarity threshold: Start at 0.9
- User-specific vs. global scope
- Freshness rules
- Context inclusion strategy
Expected Savings: Additional 15–25% reduction
Tier 3: Partial / Chunk-Based Cache
Services: Amazon S3 + DynamoDB
- Stores reusable components
- Ideal for templates, pricing blocks, definitions
- 5–10% additional savings
Intelligent Cache Management Strategies
Cache Warming
- Predictive warming using historical data
- Scheduled warming before peak traffic
- User-specific warming for premium accounts
Eviction and Refresh Policies
1. Cache Hit Rate Monitoring
↓
2. Cache Miss Analysis
↓
3. Pattern Recognition
↓
4. Rule and TTL Optimization
↓
5. Validation and Testing
↓
6. Deployment
↓
(Repeat) Monitoring and Optimization
Track these key metrics continuously:
| Metric | Target | Why It Matters |
| Cache Hit Rate | >70% overall | Direct cost reduction |
| Latency (P95) | <200ms | User experience |
| Cost Per Query | Decreasing | ROI validation |
| Quality Score | >90% | Prevents degradation |
Real-World Cost Calculation
- 10M queries/month × $0.002 = $20,000 (LLM costs)
- Infrastructure: $5,000
- Total: $25,000/month
- 3M LLM calls × $0.002 = $6,000
- Caching infrastructure: $2,500
- Total: $8,500/month
- Monthly: $16,500 (66% reduction)
- Annual: $198,000
- Payback Period: ~2 weeks
At enterprise scale (100M+ queries), this translates to hundreds of thousands of dollars saved monthly.
Common Pitfalls (And How to Avoid Them)
Over-Caching
Use content-specific TTLs.
Under-Caching
Expand the scope gradually based on misanalysis.
Cache Pollution
Add quality gates and feedback loops.
Stale Data
Use version-aware cache keys and proactive invalidation.
Organizational Challenges
Secure upfront infrastructure investment
Address team concerns about quality
Build proper monitoring into the cache layer
Cross-train teams
Conclusion:
Caching Is No Longer Optional. Large language models are powerful, but uncontrolled usage leads to runaway costs.
By implementing intelligent, multi-layer caching in your AWS AI architecture, you can:
- Reduce LLM inference costs by 40–70%
- Improve latency
- Increase reliability
- Scale sustainably
Caching is no longer a secondary optimization. It is a foundational design principle for any production-grade LLM application on AWS.
When you treat LLM outputs as reusable assets instead of disposable computations, you unlock sustainable AI economics.
The AWS ecosystem already provides the tools.
What differentiates successful teams is a deliberate caching strategy, continuous optimization, and long-term cost-aware AI design.